Using SQL Ranking Functions
Ranking functions return a ranking value for each row in a partition. Depending on the function that is used, some rows might receive the same value as other rows. Below are the ranking functions implemented in BI Server SQL.
RANK
Returns the rank of each row within the partition of the dataset. The rank of a row is one plus the number of ranks that come before the row in question. If two or more rows tie for a rank (i.e.: they have the same value of the ORDER BY expression), each tied row receives the same rank. The next row that is not tied will receive the previous rank plus the number in the previous rank as its own rank.
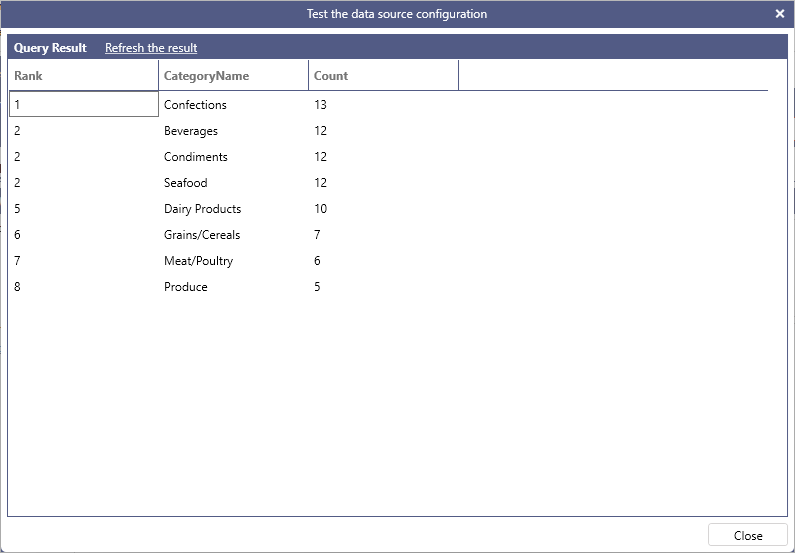
The following query ranks categories based on the number of products that belong to them. Notice that categories with the same number of products have the same rank.
Example:
SELECT
RANK() OVER (ORDER BY [Count] DESC) AS [Rank],
CategoryName,
[Count]
FROM
(
SELECT
COUNT(*) AS [Count],
CategoryName
FROM
Products AS p INNER JOIN Categories AS c ON p.CategoryID = c.CategoryID
GROUP BY
CategoryName
) AS t
DENSE_RANK
This function returns the rank of each row within a partition with no gaps in the ranking values. The rank of a specific row is one plus the number of distinct rank values that come before that specific row. If two or more rows tie for a rank (i.e.: they have the same value of the ORDER BY expression), each tied row receives the same rank. The next row that is not tied will receive the number of distinct rows that come before the row in question plus one as its own rank.
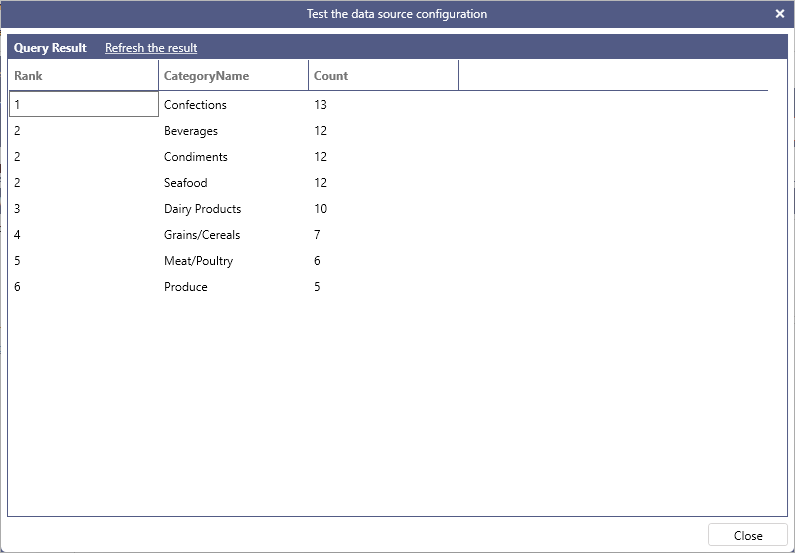
The following query dense ranks categories based on the number of products that belong to them.
Example:
SELECT
DENSE_RANK() OVER (ORDER BY [Count] DESC) AS [Rank],
OrderedCategories.CategoryName,
[Count]
FROM
(
SELECT
COUNT(*) AS [Count],
CategoryName
FROM
Products AS p INNER JOIN Categories AS c ON p.CategoryID = c.CategoryID
GROUP BY
CategoryName
)
AS OrderedCategories
ROW_NUMBER
Numbers the output of a result set by returning the sequential number of a row within a partition of a dataset, starting at 1 for the first row in each partition.
- Values of the partitioned column are unique
- Values of the ORDER BY columns are unique
- Combinations of values of the partition column and ORDER BY columns are unique
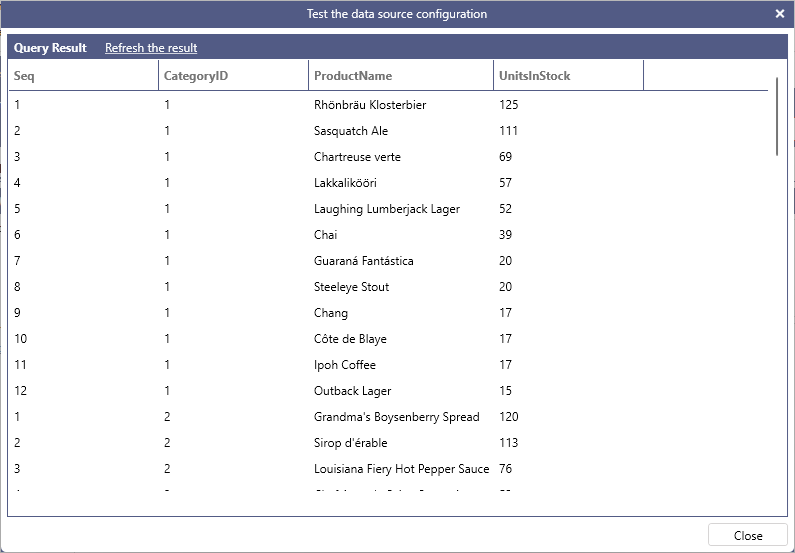
The following query assigns a sequence number to products partitioned by CategoryID and ordered by UnitsInStock:
Example:
SELECT
ROW_NUMBER() OVER (PARTITION BY CategoryID ORDER BY UnitsInStock DESC) AS [Seq],
CategoryID,
ProductName,
UnitsInStock
FROM
Products
NTILE
Distributes rows in a partition into the specified number of groups, numbered starting at one. For each row, NTILE returns the number of the group to which the row belongs. If the number of rows in the dataset is not divisible by the number of desired groups, it will cause groups of two sizes that differ by one member. Larger groups come before smaller groups in the order specified by the OVER clause. For example, if the dataset number of rows is 13 and the number of groups is 3, the first group will have 5 rows and the remaining two groups will have 4 rows.
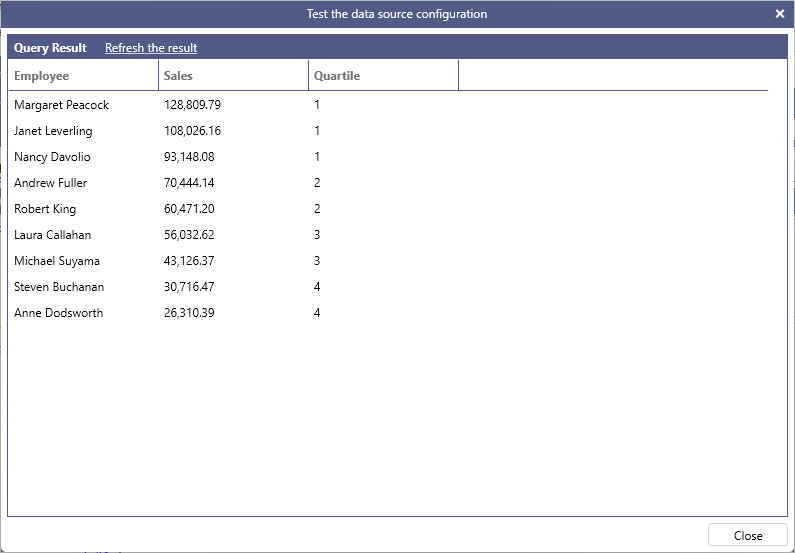
The following query divides employees into four groups based on sales for the year 1997.
Example:
SELECT
Employee,
toformat(Sales, 'n') AS Sales,
NTILE(4) OVER (ORDER BY Sales DESC) AS Quartile
FROM
(
SELECT
SUM(Quantity * UnitPrice * (1 - Discount)) AS Sales,
FirstName + ' ' + LastName AS Employee
FROM
Orders AS o INNER JOIN OrderDetails AS od ON o.OrderID = od.OrderID
INNER JOIN
Employees AS e ON e.EmployeeID = o.EmployeeID
WHERE
year(OrderDate) = 1997
) AS t