Introduction to BI Server
The BI Server is a component within GENESIS that you can use to organize your data into data structures. Once organized, you can then query those datasets throughout other components in GENESIS, including visualization. Queries are structured in a SQL-like syntax and these queries can be created ad-hoc or in a configured data view, allowing you to standardize the output of your datasets.
You might use BI data models to organize your data to allow for aggregating data according to asset attributes, filtering or grouping according to different criteria, or as a means to do analysis on historical faults or alarms, among other uses.
Key Benefits
-
Performance The built-in in-memory data compression caches data resulting in high speed data retrieval of complex data shapes.
-
Flexible Data Access All types of application data, from real time data to alarm or historical data, can be accessed via a unified and easy to use interface.
-
ETL Support Extensive Extract, Transform, Load (ETL) support to customize the shape of raw application data into operator-friendly visualizations.
-
Flexible Data Updates Flexible scheduling of data updates, whether a complete data source refresh is needed or an incremental type of application deployment.
-
Data Modelling Data models enable you to synthesize simplified views of complex application data.
-
SQL Language Extensive SQL-like query support to allow for a familiar, relational database type of development of tables, views and data models.
-
Parameters Parameters to allow you to customize data retrieval from defined data views.
-
Data Retention Policies There are several policies to let you control and customize the data retention options and to maintain peak performance in runtime.
-
Data Grouping You can group categories of data for easily creating meaningful runtime visualizations.
Core Elements and Architecture
In this section, we will dive a bit more inside the BI Server internals, architecture and core elements.
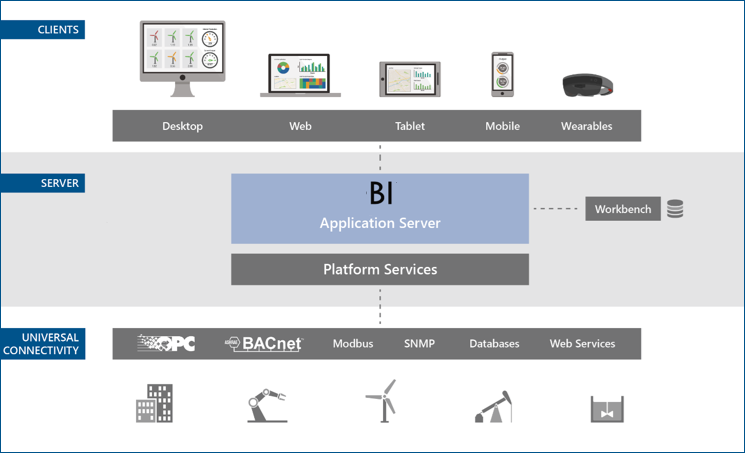
BI Server uses the data layer of GENESIS to have connectivity to all types of data sources. At the same time, BI Server exposes all the data via the native GENESIS client API, which allows for the integration with visual and/or reporting clients.
There are many ways to use BI Server, but the diagram below outlines the most common and most powerful architecture and the way the pieces are designed to work together. Following the data from the bottom up, your originating data sources can be just about any piece of data that GENESIS can connect to, whether it be OPC, web services, Data Historian, Assets or a custom database. This data is pulled into Data Flows. Each Data Flow is configured as a sequence of steps to modify and shape the data to result in a dataset to your liking.
Once the data has been shaped by Data Flows, it is pulled into Data Tables inside a Data Model. The Data Model defines relationships between the Tables. These relationships make it easy to query the data, you can think of them like foreign key relationships in SQL.
Data Models cache the data in memory. Data from a Data Model can either be queried directly by clients, or you can create a predefined query in the form of a Data View. Data Views can be based on the Data Tables or on other Views. The Relationship links between Data Tables make it easy to configure queries without having to explicitly join Tables manually.
Lastly, Triggers may be used to control the refresh of a Data Table.
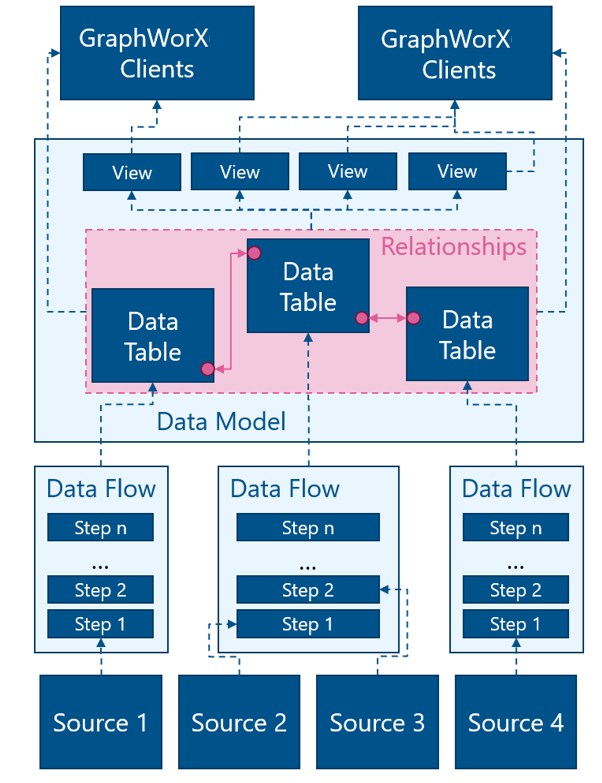
The elements of BI Server are:
-
Data Flows
-
First step in connecting to any data source and performing data manipulations such as transformation, adding or deleting columns and more.
-
Data Flows can also have parameters to allow for dynamic data customization, such as start and end times of historical data retrieval.
-
-
Data Model
-
They represent a logical grouping of your data to allow for user-friendly manipulation and customization. In relational database terms, they represent an SQL database.
-
-
Data Tables
-
In terms of functionality they are similar to a database table.
-
They are created from Data Flows and the user can select a column or a combination of columns to define a Primary Key on the Data Table.
-
They can have triggers to set policies for data refreshes and updates.
-
-
Data Relationships
-
They represent logical relationships between Data Tables based on Primary Keys or common columns.
-
They improve the processing speed of Data Views.
-
-
Data Views
-
They provide customized views of Data Tables and they are created using SQL syntax, similar in concept with a relational database stored procedure.
-