Performance Calculation Enhancements
The following major enhancements have been implemented:
Functions: Nextevent, Resetevent and Isevent
New expression functions have been added: nextevent, resetevent and isevent.
These new functions are designed to allow periodic processing based on some other event (a value change, etc.). Previously, the user would have to create very fast time-based functions and use logic in the calculation itself to see if the process needed to be completed.
Here is an example use case scenario. We have a Boolean value named Start, which determines whether a product line is making product. When it is in production, we need to make periodic calculations to monitor the production line. We also need to know when the line started and stopped production.
First, create a calculation trigger as a data trigger. Select “Trigger On” as “Expression”. Then, use the following expression:
IF {{data:Calc.Start}} THEN nextevent(5000, (IF !isevent() THEN 1 ELSE 2)) ELSE resetevent(3)
Second, create a performance calculation and add the created trigger to the list of triggers in the “Triggers” section. This performance calculation will run based on created trigger events and the trigger value will contain one of the following values:
-
Production line started
-
Periodic check when production line is in production
-
Production line stopped
The trigger value can then be used in your performance calculation tag's logic.
Function Libraries
A Function Library is represented by a public .NET class, where all public methods can be used as “calculation methods” inside Hyper Historian. A single assembly can contain one or more function libraries (public .NET classes).
Relative Data Variable References
Prior to Version 10.8, Data Variables used in Performance Calculations had to use fully qualified names, i.e. a set of browse names starting in the address space root, separated by a dot (.) .
Hyper Historian Address Space
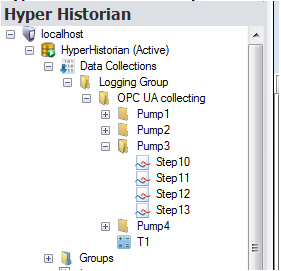
A data point with the name “Step10” from the figure above using a fully qualified name can be specified as:
{{data:LogGrp.OPCUA.Pump3.Step10}}
or
{{LogGrp.OPCUA.Pump3.Step10}}
It is now possible to specify such names relatively to the hosting calculation. The syntax to specify “current hosting folder” or “parent folder” is identical to the file system syntax:
-
a single dot (.) specifies the calculation’s hosting folder
-
double dots (..) specify the “parent folder”
Thus, the point name “Step10” (see the "Hyper Historian Address Space" figure above) located in the calculation “T1” may use the following syntax:
{{?data:./Pump3/Step10}}
or
{{?./Pump3/Step10}}
...where ‘?’ identifies a new point syntax (the name delimiters have changed from ‘.’ to ‘/’) and the ‘dot’ saying to start in the hosting calculation folder.
New Value Array Functions
New array functions mainly add a possibility to read the most recent values from multiple data variables and return it as an array. This array can be processed by other functions (a name starting with a character) such as amin, amax, amed, aavg, etc.
If multiple operations with this array are required in a single expression (e.g. finding min and max), it is strongly recommended to cache the created value array in a “local” expression variable – calling function setvalue({{myVariable}}, atagnow3(..)).
Functions atagnowN(variable_name1, variable_name2, ..)
This is a set of functions (currently N is between 3 and 6) to read the most recent values for the given number of variables.
Parameters:
-
Data Variable Name: Standard data variable name – can be either fully qualified or relative to hosting calculation.
Returns:
Data values array, which can be processed by standard array functions, such as amin(), amax(), avg(), etc.
Example:
Assume a calculating average from the most recent values “Step11”, “Step12” and “Step13” in calculation “T1” (see the "Hyper Historian Address Space" image above).
x=aavg(atagnow3(“./Pump3/Step11”, “./Pump3/Step12”, “./Pump3/Step13”))
Function atagnowf(path_filter, name_filter, variable_types)
This function reads the most recent values for all data variables found in the address space based on passed filter strings – variable path and variable name.
Parameters:
-
Path Filter: A string set of path names separated by a slash character (/). Names can be either fully qualified or can use wildcard characters as a folder filter (see the Filter Pattern Syntax section below). The path can be relative to the hosting calculation.
-
Name Filter: A string, data variable name filter.
-
Variable Types: A string, where each character specifies a single data variable type. When empty, it then specifies all variable types (collected, calculated and aggregated). Valid characters are: A..aggregated variables, R..Collected (raw) variables, C..Calculated variables.
Returns:
Data values array, which can be processed by standard array functions, such as amin(), amax(), avg(), etc.
Example:
Assume a calculating average from the most recent values “Step11”, “Step12” and “Step13” in calculation “T1” (see the "Hyper Historian Address Space" image above).
x=aavg(atagnowf(“./Pump3”, “Step1[1-3]”, “R”))
Filter Pattern Syntax
Pattern Options
The pattern-matching features allow you to match each character in a string against a specific character, a wildcard character, a character list, or a character range. The following table shows the characters allowed in the pattern and what they match.
|
Characters in Pattern |
Matches in String |
|
? |
Any single character |
|
* |
Zero or more characters |
|
# |
Any single digit (0–9) |
|
[ charlist ] |
Any single character in charlist |
|
[! charlist ] |
Any single character not in charlist |
Character Lists
A group of one or more characters (charlist) enclosed in brackets ([ ]) can be used to match any single character in a string and can include almost any character code, including digits.
An exclamation point (!) at the beginning of the charlist means that a match is made if any character, except the characters in the charlist, is found in string. When used outside brackets, the exclamation point matches itself.
Character Ranges
By using a hyphen (–) to separate the lower and upper bounds of the range, the charlist can specify a range of characters. For example, [A–Z] results in a match if the corresponding character position in the string contains any character within the range A–Z, and [!H–L] results in a match if the corresponding character position contains any character outside the range H–L.
When you specify a range of characters, they must appear in ascending sort order, that is, from lowest to highest. Thus, [A–Z] is a valid pattern, but [Z–A] is not.
Multiple Character Ranges
To specify multiple ranges for the same character position, put them within the same brackets without delimiters. For example, [A–CX–Z] results in a match if the corresponding character position in the string contains any character within either the range A–C or the range X–Z.
Usage of the Hyphen
A hyphen (–) can appear either at the beginning (after an exclamation point, if any) or at the end of the charlist to match itself. In any other location, the hyphen identifies a range of characters delimited by the characters on either side of the hyphen.
See Also:
Performance Calculation Functions