About AnalytiX-BI Server
![]()
The landscape of data in today’s applications is of very diverse nature: systems are made of a large variety of components, many of which have their own data storage and their own interface to provide access to stored data – whether it is a web service, a database, an historian, etc.
This scattering of information often makes it difficult to provide a cohesive view of a system and, even in cases where all the data can be visualized together, it might not be shaped logically for the end user. Correlating these different datasets with each other is challenging and trying to query them using a common set of filters or parameters is difficult.
AnalytiX-BI was created to address these problems. Data is organized in user-defined Data Models,representing collections of datasets that are logically related to each other, irrespective of their physical origin. Data Models are connection to actual data usingData Flows; ETL processes that allow multi-step transformations of the ingested data for better shaping and filtering before loading it in a model.
AnalytiX-BI Architecture
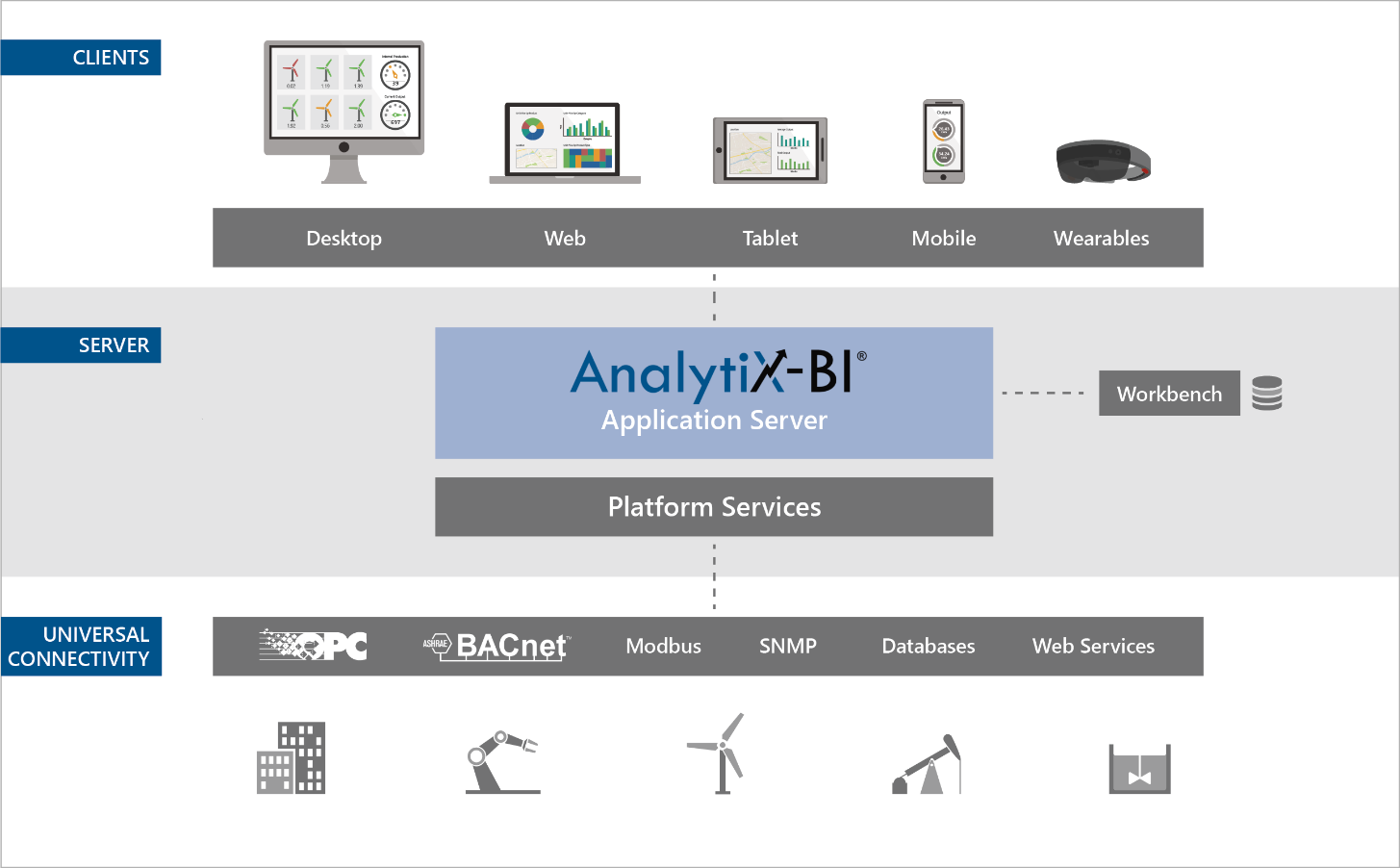
AnalytiX-BI Overview
There are many ways to use AnalytiX-BI, but the diagram below outlines the most common and most powerful architecture, and the way the pieces are designed to work together.
Following the data from the bottom up, your originating data sources can be just about any piece of data that ICONICS can connect to, whether it be OPC, web services, Hyper Historian, AssetWorX, or a custom database. This data is pulled into data flows. Each data flow is a sequence of steps to modify and shape the data to best fit the data model. Data flows can be parameterized, so clients can get only the specific data they need.
Note: Data flows are not cached. Each time a data flow is accessed, the data is read from the data sources anew and all steps are followed.
Once the data has been shaped by data flows, it is pulled into data tables inside a data model. The data model defines relationships between the tables. These relationships make it easy to query the data. Data models cache the data, and use a number of techniques to optimize memory use and performance. (See Performance Considerations.)
Data from a data model can either be queried directly by clients such as GraphWorX64 or KPIWorX, or the user can predefine views for a data model. Views can be based on the data tables, or on other views. Due to the predefined relationships, it is very easy to query the data model without having to worry about the proper JOINs between tables.
Since the data model is cached, triggers can be defined on each data table in the model to re-query its data source. Triggers can tell the table to be dropped and recreated anew, or only update the records that have changed. Each table can have multiple triggers, so you can define the best scheme to ensure your table is refreshed in the manner best suited for it. Triggers can work with parameters of data flows to only pull in data since the last data model refresh.
AnalytiX-BI Architecture
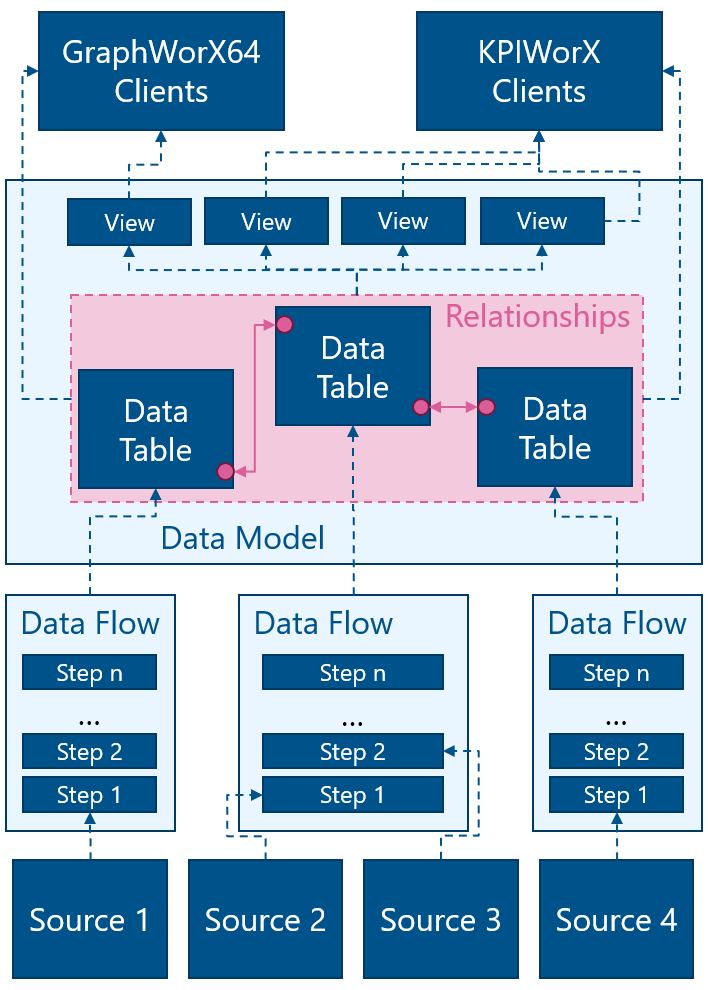
This architecture takes full advantage of all the features of AnalytiX-BI, but it is flexible, and many of its parts are optional. If there is no need to shape or parameterize your data, you can pull a data source directly into a table inside a data model without using a data flow. You can connect your clients directly to data flows without a data model if you only need to do some shaping and have no need to cache the data. You can forego views, and simply connect your clients directly to the model, writing your query within a point name.
See Also: